The National Institute of Standards and Technology released a report today about the accuracy of facial recognition software. The news was grim: most algorithms make a lot more errors when the subject is anything other than a white male, which means that women and people of color are more likely to be misidentified. But this got me curious: this might be the average result, but how do different algorithms stack up? Which one is the best at identifying all kinds of people equally well?
The full report is here. Figure 13 turns out to have what I was looking for:
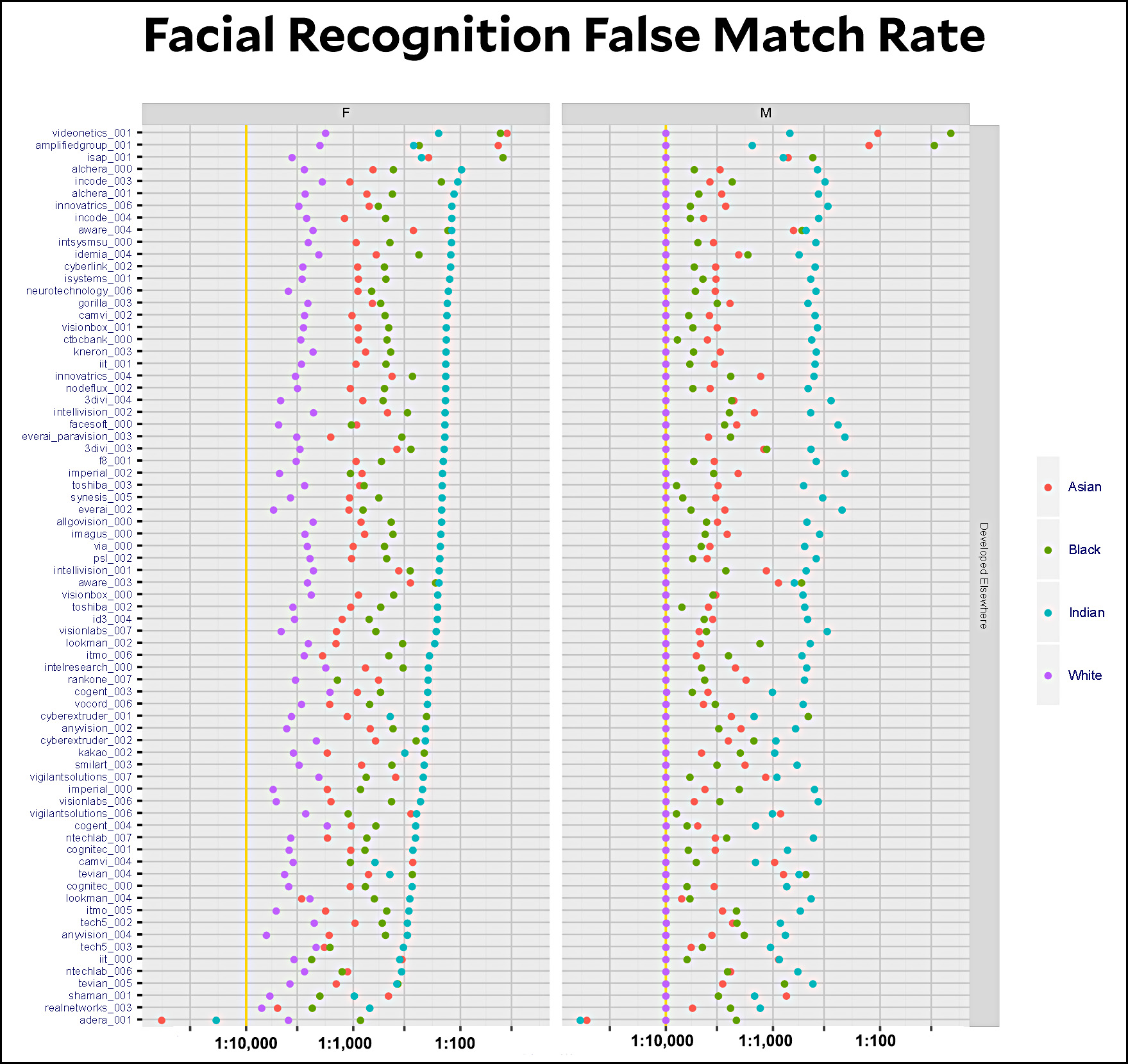
The test was calibrated so that its error rate on white men was 1:10,000 for each algorithm (those are the purple dots on the right). Every other test is run with the same calibration, so the red, green, and teal dots show how much worse the error rate is for anyone who’s not a white man.
What surprised me was that pretty much all the algorithms are equally bad. There are a handful that do OK with Asian and black men (tech5_003, lookman_004, cogent_004, incode_004), but that’s it. With one exception (the adera_001 algorithm at the very bottom) the best that any of them do with American Indian men is five times worse than for white men. Recognition of women is worse than men across the board.
If we want better results, it looks like we’re going to have to use a Chinese-developed algorithm. Here’s how they rate:
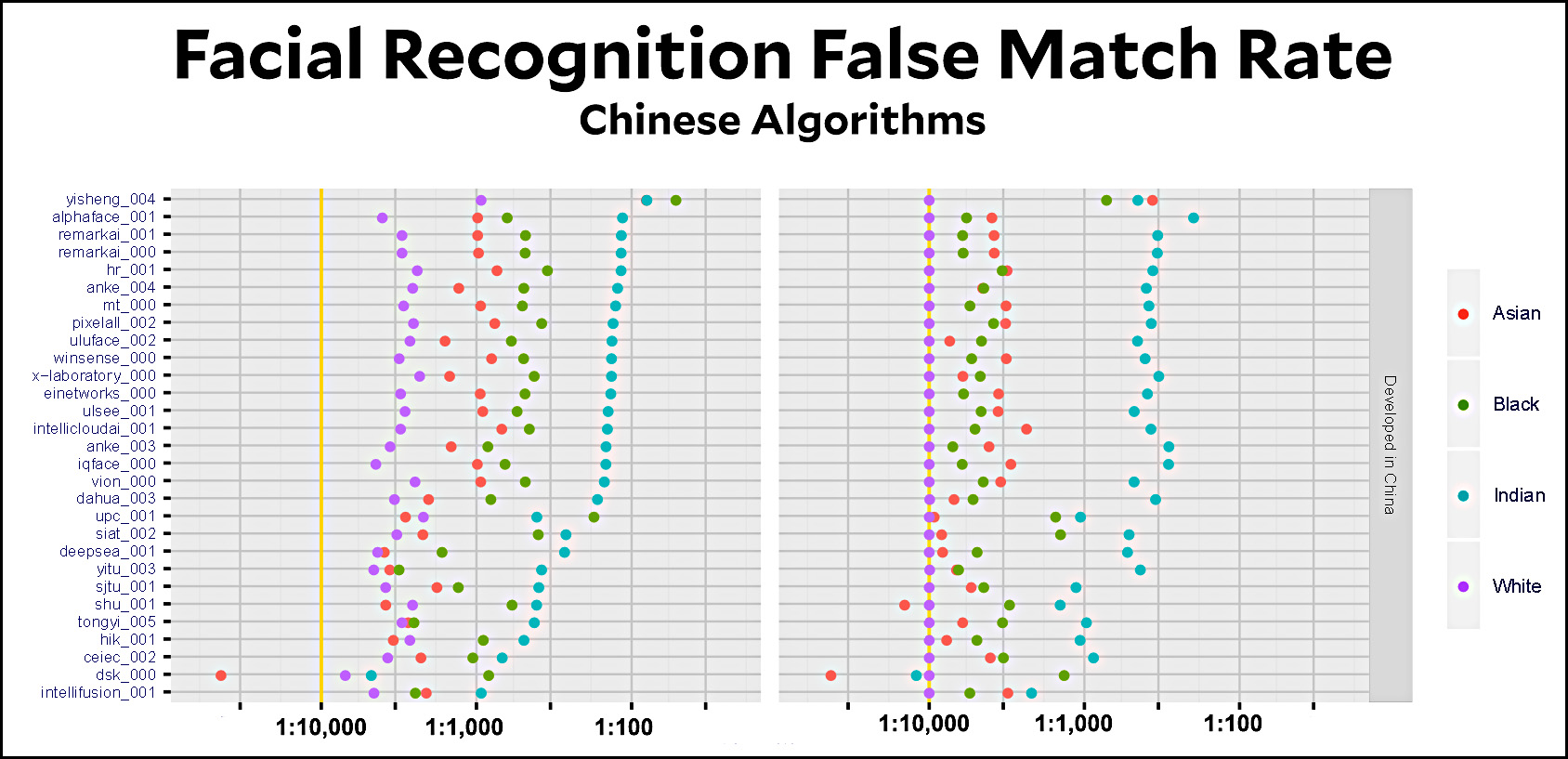
Surprisingly, the Chinese algorithms seem to be no better on average. Especially surprisingly, they appear to be only slightly better even for Asian faces. Is this because of algorithm failures or because they’re training on datasets similar to what everyone else uses? Since the algorithms are all proprietary, there’s no way of telling. But this report sure shows that the facial recognition industry is broken from the roots up.