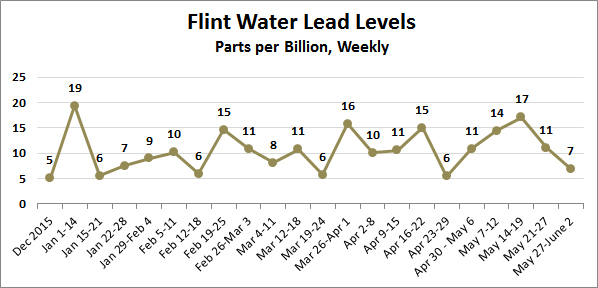
Here is this week’s Flint water report. As usual, I’ve eliminated outlier readings above 2,000 parts per billion, since there are very few of them and they can affect the averages in misleading ways. During the week, DEQ took 383 samples. The average for the past week was 6.91.
POSTSCRIPT: A number of people have asked why I eliminate outlier readings and then take the mean value. Why not just use the median? Here is last week’s dataset of lead readings from Flint:
0,0,0,0,0…[197 zeroes]…1,1,1…[40 ones]…2,2…[23 twos]…175,194,219,977
This is typical: Lots and lots of zeroes and ones, and a small number of readings over ten. The median is zero. It’s always zero. So the median doesn’t tell you anything.
That said, there are several alternatives. For example, I could just report the percentage of tests over 15 ppb, which is the EPA “action level.” This week it was 6.0 percent. Or I could report the 90th percentile level, which is a common testing method for lead in water. This week it was 7 ppb. Both of these measures are going to be pretty much the same from week to week because they don’t give any special weight to the small number of very high readings. On the other hand, the mean might give too much weight to the high readings, even after I remove the readings over 2,000 (usually there’s no more than one of those per week).
Bottom line: there are several reasonable ways of doing this, and they all have pros and cons. The only one that’s completely useless, however, is the median. It tells you nothing.